Hopefully that quick info was enough to help you address your immediate problem, @tomsmyth. I do also want to give a broader update about large datasets in ODK since I don't think that information exists in one place currently. This question ties in to conversations happening about more sophisticated data workflows. In particular, the TSC has been exploring options for adding some kind of case management and that will likely rely on a case list managed as an external document. @adam.butler has been working on a spec at https://github.com/opendatakit/roadmap/issues/23 and I know @Tino_Kreutzer and the folks at Kobo are also interested in this broad topic. @martijnr has also been involved in related conversations and generally really helped me understand the state of things.
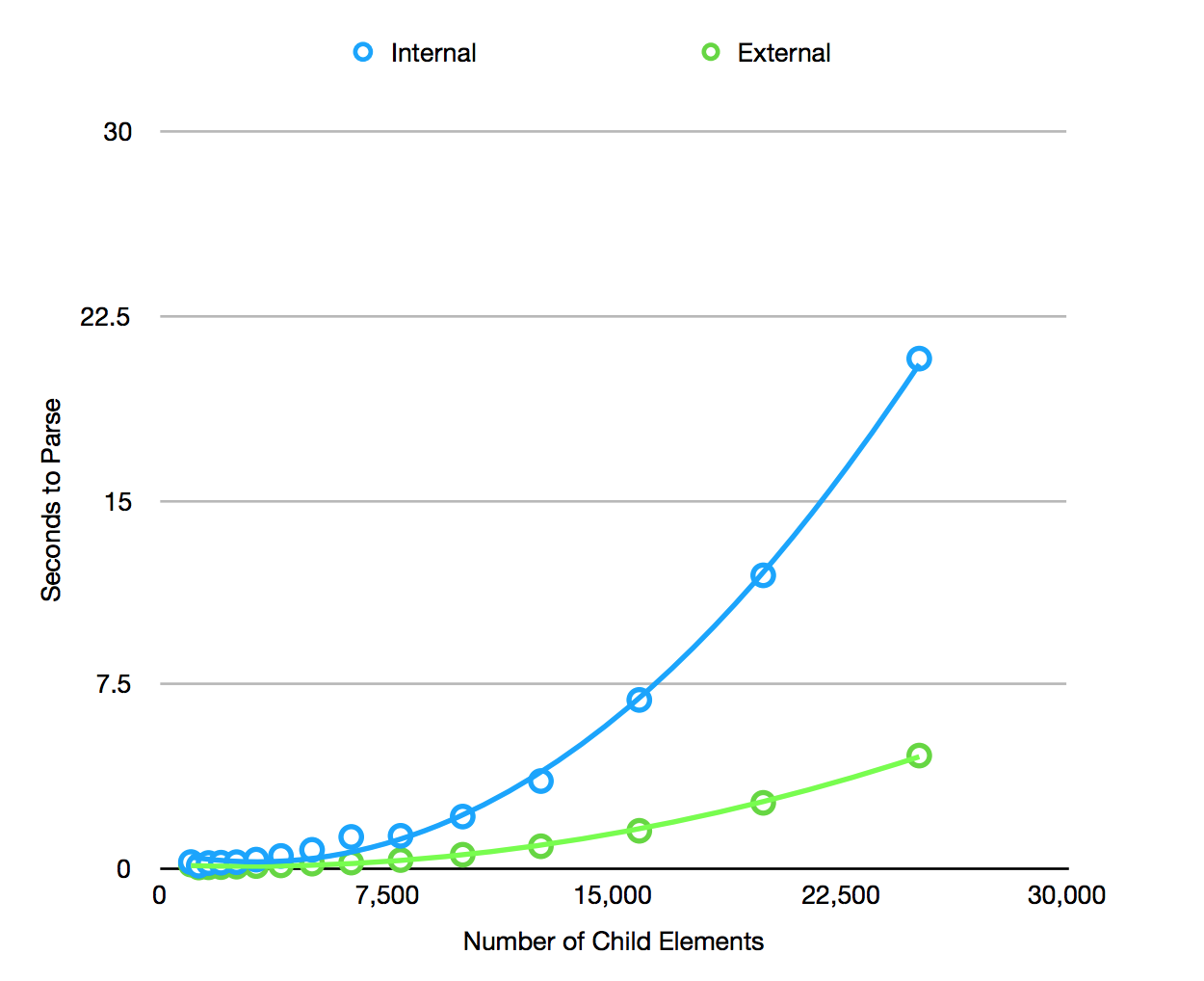
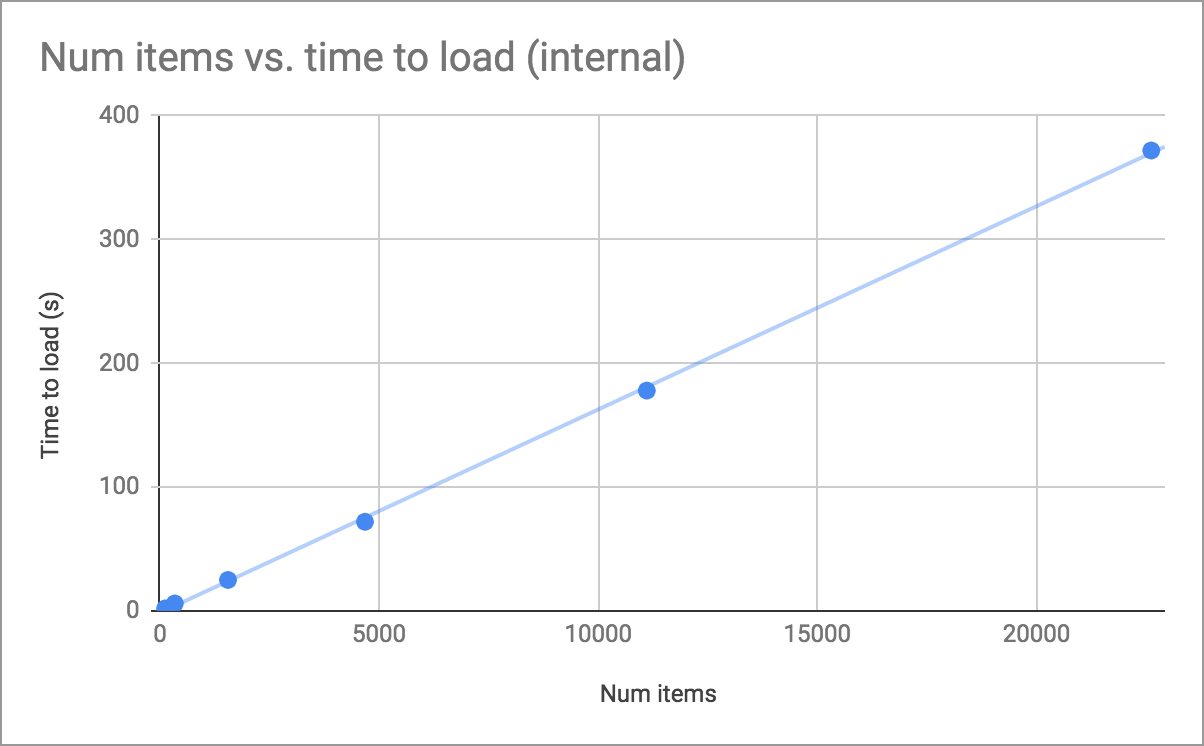
I first want to point out that large datasets directly in the form have gotten a lot more performant over the last year thanks to work by @dcbriccetti. So I do recommend trying an internal dataset first as this is simpler to deal with and non-controversial. Those datasets can be updated without having to change the form_id and Collect can can automatically pull those updates (see general settings > Form management > form updates). Depending on the device and specific usage, this can be performant enough for 1000s of data elements.
There are currently 3 incompatible approaches to external data supported by ODK Collect.
External secondary instances
As documented in the ODK XForms specification. This approach is entirely consistent with how datasets in the form are handled. That means everything that works with internal choices also works with external choices including choice filters for cascading selects and any kind of complex XPath querying. This is the only option for external data that is part of the ODK XForms spec. It is supported in ODK Collect and in Enketo. It does have two major downsides: clumsiness of the XML format and performance.
XML is not reasonable to create by hand. For this to be a viable way to represent external data, there needs to be some way to go from tabular data to an XML doc. This could be done server-side, for example. XLSForm could also be able to generate XML external instances just like it builds CSVs for external itemsets. Related to all this is @martijnr's proposal to formally introduce a way to attach a CSV file that would be queryable in the same way as the XML (by, for example, generating the XML on the device). The proposed spec is described in xforms-spec#88.
This works well for mid-size datasets but because the whole XML doc is currently represented and queried in memory in the Collect implementation, it can become quite slow for large datasets or slow devices. @dcbriccetti made some great improvements to performance about a year ago and there are probably more to make without big changes to the code structure. There are likely larger changes possible such as not holding the whole doc in memory or maybe even using a database.
search() and pulldata()
As documented in the XLSForm spec and with more details here. These predate external secondary instances and have no grounding in the ODK XForms spec. As I understand it, the two major design criteria were fast loading of large datasets and minimal changes needed to existing tools, especially pyxform. I think that's what led to the unexpected choice to make search() an appearance. Implementation-wise, this approach takes a CSV, loads it into a database table and then makes queries against it. search() entirely bypasses the form structure and injects the values from a database into a list of options for a select. pulldata() behaves roughly like a normal XPath function and makes it possible to pull a single value out of the database and use it in some expression.
These are performant but have limitations like the one @tomsmyth pointed to because the data is not part of the form. SurveyCTO (company that builds tools on top of ODK) contributed this and I know they have implemented some form of case management on top of it.
Fast external itemsets
As documented in the XLSForm spec. This implementation also predates external secondary instances and I think was added roughly at the same time as search()/pulldata() to solve the same problem of making large choice sets performant. It also has no grounding in the ODK XForms spec and works in a similar way -- Collect puts the contents of a CSV named itemsets.csv into a database and then queries it. It's more limited than search()/pulldata() and narrowly solves the problem of speeding up cascading selects. It only works with select ones (not even select multiples). I don't think it would be appropriate for representing general datasets like case lists.